"Step and repeat translating" optimization? #327
Comments
|
Any chance you could build from master and compare? |
|
Will do, but probably not today. I'll let you know about results. |
|
Also, you can try https://github.com/Evil-Spirit/solvespace-master/commits/master, this should be faster |
|
Tried master branch, feels much faster when just browsing model, but still painfully slow when doing any actual changes (or even no changes, but attempt to do them on 0 DOF model). This is with model duplicated 3 times in one scene with some minor stuff on top: Looks like some kind of math is happening and it takes a lot of time to compute the result. @Evil-Spirit, can't compile your fork, probably some other dependencies are needed to be installed: |
|
@nazar-pc hm. I think you can find more information here Evil-Spirit#1 |
|
@Evil-Spirit, dependencies list and configuration/compilation steps are the same. Anyway, there is a model in the first comment, you can try it yourself and check how responsive it is. |
|
Ofc I have tried but I can't actually understand the usecase where you getting your results. Can you explain? |
|
I want to get an effect similar to one on the back of this PSU:
I'll have 3 such areas of size 140x560 and one 140x420, hence I need to duplicate model from the first comment 15 times. |

|
I mean what are you doing with your sketch to get performance problem. Which group? What action? |
|
I'm using "New group linking / assembling file" to add file from the first comment 3 times to the scene (or whatever it is called properly). That alone is already enough to make any changes super slow. |
|
So, you are creating new file and linking file fan_holes 3 times or using step and repeat? what kind of operation you are using (difference/union/assembly?) |
|
Can you attach all the files or minimal assembly example where you are getting issues? |
This. Step and repeat is used in fan_holes file.
Assemble, it is selected by default. |
|
The problem is not step and reapeat itself, the problem is in linked file (actually this issue will be reproduced with any linked file with huge amount of entities). Performance issues is caused by Group::Remap function and obviously it can and should be optimized. @jwesthues can we just make map<input, map<copyNumber, EntityId>> to optimize? |
|
Ofc if you have any performance issues you should always switch off "edges of solid model" Not sure if this work correct, but this is faster: hEntity Group::Remap(hEntity in, int copyNumber) {
if(remapMap.find(in.v) != remapMap.end() &&
remapMap[in.v].find(copyNumber) != remapMap[in.v].end())
{
return h.entity(remapMap[in.v][copyNumber].h.v);
}
// And if we still don't find it, then create a new entry.
EntityMap em;
em.input = in;
em.copyNumber = copyNumber;
remap.AddAndAssignId(&em);
remapMap[in.v][copyNumber] = em;
return h.entity(em.h.v);
} |

|
The present implementation will indeed get crazy slow when the fixed-size hash table fills up. You should be able to replace that with any kind of index keyed by {in.v, copyNumber}, with no surprising consequences elsewhere. |
|
Hm, why don't we replace it with |
|
Ofc this will be better. I just make prototype to understand weather that will be better or not. |
|
Is this a big undertaking? I have a model that takes about 1 minute to apply any changes, especially when reverting changes. I'd be happy to test if someone can prepare a patch. |
|
@nazar-pc the fix is working. but still not integrated. |
|
@nazar-pc Not a very big undertaking, the fix just needs to be cleaned up a bit. I'll look into it soon. |
|
So few months later, is there a PR already? |
|
@jwesthues Why do you save remap table to the file? Isn't it deterministic? Is that done just so that code can be changed freely without regard to the order of generation of remapped entities? |
|
Consider the case where we:
If we lost the remap table and regenerated it from scratch, then the constraint would now reference C', since that's now the second entity in the group. We need to preserve that remap table state, in order to preserve our associations when entities in the source groups get deleted. |
|
@jwesthues Thanks! @nazar-pc Sorry for the delay, I wasn't feeling well. I've implemented this in bd84bc1. On your file the load time is about 25% less, so it's not a huge improvement, but quite noticeable. |
|
Just for information: NoteCAD uses the different approach for creating ids - IdPath Every entity/constraint/group have it's own locally unique id, so we can address them by path like in filesystem: <!-- id = 0 means root of current adrdessation context -->
<detail id="0">
<feature type="SketchFeature" id="E" source="D">
<entities>
<entity type="PointEntity" id="3"... />
<entity type="PointEntity" id="5" ... />
</entities>
<constraints>
<constraint type="PointsCoincident" id="7">
<!-- Here we have a path: since 0 is id of current detail,
we have start to search inside detail for "E" id, inside
feature, we get sketch "-1" and it means we get user-drawn
sketch which exist for almost any group.
Then we get entity "3" and "5".-->
<link path="E/-1/3" />
<link path="E/-1/5" />
</constraint>
</constraints>
</feature>
</detail>So, If we will import this file into assembly nothing will be changed for ids, but just one "folder" will be prepended to path. <feature type="SketchFeature" id="2" solveParent="False">
<entities>
<entity type="LineEntity" id="14" style="1">
<entity type="PointEntity" id="15" ... />
<entity type="PointEntity" id="16" ... />
</entity>
</entities>
</feature>
<feature type="ExtrusionFeature" id="3" source="2" op="Union" .../>
<feature type="SketchFeature" id="4" source="3">
<references>
<!-- here we use the following adressation: -->
<ref name="u" path="3/15:2" /> <!-- :2 - line of extruded point from source("2") of extrusion ("3") group -->
<ref name="v" path="3/14:1" /> <!-- :1 - entity from source of group "3" ("2"), shifted in extrusion direction-->
<ref name="o" path="3/15" /> <!-- :0 or can be omitted - copy of original entity from "2">
</references>
</feature>Also, this approach allow us not to create all the entities like in SolveSpace. In NoteCAD there is no any GenerateAll (entities for each extrude/revolve group). We can use "lazy" entity creation by request. For example, in NoteCAD there are two types of reqeusts: geometric request (hovering) and request by id. The following image demonstrates some geometrical request inside 4xLinearArray of some sketch.
|
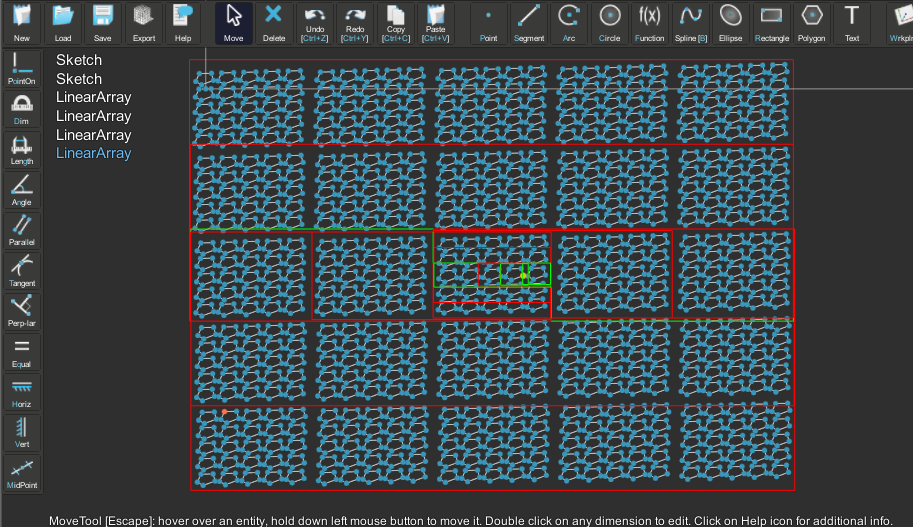
|
Yeah, that definitely has its benefits. But SolveSpace has to open old files, so any new scheme needs a migration path from an old scheme. |
|
I noticed that the save file format appears to block other improvements as well. Not to say you have the time for this (thanks for the recent great push forward for v3!), but it seems like versioning and forking the slvs format might be a good idea. |
I think you misunderstand the nature of the issue here. Of course making an incompatible change to the slvs format is necessary for evolution, and this will be done (#75). But it is unthinkable that there will be no migration path from "old slvs" to "new slvs"; that would leave all of SolveSpace's loyal users out in the cold. Since the remap information cannot be regenerated from other information in the file, that means whatever the new file format is, it has to have a mapping from the old file format. It can't just be a clean break. Moreover, 2/3 of the problems with the current file format is that a) it is an 1:1 match for the internal data structures, and b) most of the information is stored in variables like "entityB" or "other" or such, which are overloaded to mean completely different things for each kind of entity, constraint, etc. This means that to make any changes to the file format or internal representation of data, it is necessary to undertake the colossal work of decoupling them from each other first. Since the test suite is very marginal (there was none before I wrote one...) it is also very hard to ensure correctness of such an enormous rewrite. That is the real challenge here. |
|
Ah, I see, thanks. For the record, I wasn’t suggesting breaking the current format— I was suggesting keeping a legacy slvs reader and creating a new reader without the inherent issues. Separate migration logic (or a separate tool, as inelegant as that might be) might work... I don’t know. Anyway, I think I understand the difficulties of such a task a bit better now. Thanks for taking the time to explain. |
System information
SolveSpace version: 2.3
Operating system: Ubuntu 18.10
Expected behavior
When opening fan holes.slvs.zip system struggles to handle it, duplicating it a few times in the same scene slows down application to the point of being unusable.
Actual behavior
Model is rather simple, it should work fast and smooth.
Additional information
I want to make holes in solid surface (cutouts for fan in a custom case design). For this I need to duplicate above model 15 times. My machine is has 12-thread i7-8700k overclocked to 4.8GHz on all cores, there is no CPU in existence much faster than that (if talking about single-core performance).
Maybe I'm doing it wrong and there is a better approach, let me know if that is the case.
The text was updated successfully, but these errors were encountered: